The Effect of Neurodegenerative Disease on the Economy of Words
This original study makes use of various word frequency metrics to investigate whether or not the progression of neurodegenerative disease affects word frequency.
Abstract
Though it is known that neurodegenerative disease affects word use and that depression impacts the number of first-person pronouns used in written text, it is yet to be seen whether or not individuals with depression have significant changes in word frequency and use as they age. This study makes use of various word frequency metrics to investigate whether or not the progression of neurodegenerative disease affects word frequency. The primary hypothesis is that that neurodegenerative disease affects original prose writing and causes texts to divert away from standard word frequency distributions as the authors age by either significantly increasing or decreasing frequency of word usage. The secondary hypothesis is that authors with depression use the word “I” more often in writing than non-depressed authors. Results demonstrated that there was no significant difference between test and control groups both in word frequency distribution and in first-person pronoun use. Future studies should aim to obtain a more robust and varied data set and construct a predictive algorithm for determining the probability of an author's depression based on their produced literature throughout their lifetime.
Introduction
Neurodegenerative disease is a massive, global, problem. According to a recent study conducted by the World Health Organization, over 250 million people worldwide currently suffer from depression (James et al, 2018). The effect of depression and other neurological disease has long been known to affect language use through speech patterns and writing. For example, in 2015, Szatloczki et al. found that even in early stage Alzheimer’s disease (AD), the temporal characteristics of patients’ speech was effected. This gave way to the development of a predictive linguistic screening test as a method of early AD diagnosis.
Furthermore, it has been known for decades that pronoun use in the writing of depressed individuals is significantly different than those without depression (Edwards and Holtzman, 2017). This finding has been well studied over time and even generalized over various types of writing, such as poetry (Striman and Pennebaker, 2001) and essays (Rude et al, 2004), among others. Concretely, depression has been shown to influence the use of first person pronouns such as “I”, with individuals with depression using significantly more first-person pronouns than those without depression (Bernard et al, 2016).
This study will investigate how word frequency and pronoun use changes as authors with neurodegenerative disease, specifically major depressive disorder (MDD), age and progress in their illness. The primary hypothesis is that neurodegenerative disease affects original prose writing and causes texts to divert away from standard word frequency distributions as the authors age by either significantly increasing or decreasing frequency of word usage. The secondary hypothesis is that authors with depression use the word “I” more often in writing than non-depressed authors.
Methods
Data Set
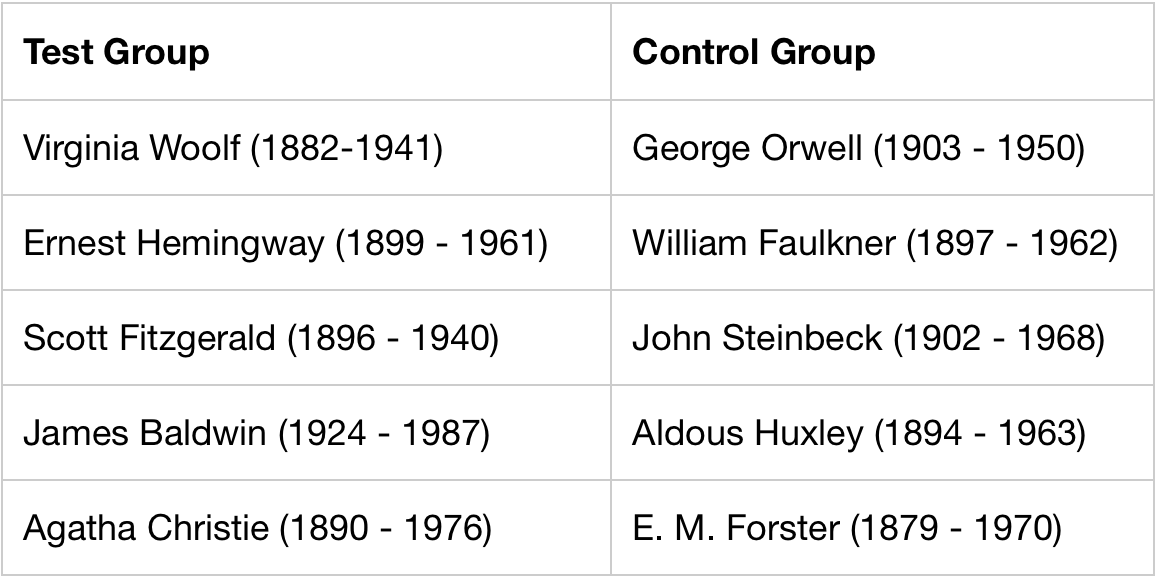
This study used the works of ten 19th and 20th century authors across a test group (n=5) and a control group (n=5). The following selection criteria were used in order to assemble the data set.
Authors must have written long form novels that are accessible in the public domain. Authors must have written a minimum of three works over the course of ten years to allow for the possibility of disease progression over time in authors selected for the test group. Authors must have written primarily in English. No translations were used as a translator may compensate for the author’s unconscious word and pronoun use. The authors selected for the test group must have strong and recurring evidence of experiencing depression in their time as a writer. Please note that due to the fact that MDD has only been a valid medical diagnosis since the mid 1970s (Phillip et al, 1991) and that the researcher of this study did not have access to the medical records of the chosen authors, anecdotal evidence of depression was used in the selection of authors and may therefore be inaccurate. It is also worth noting that selection preference was given to authors with stronger evidence for MDD.
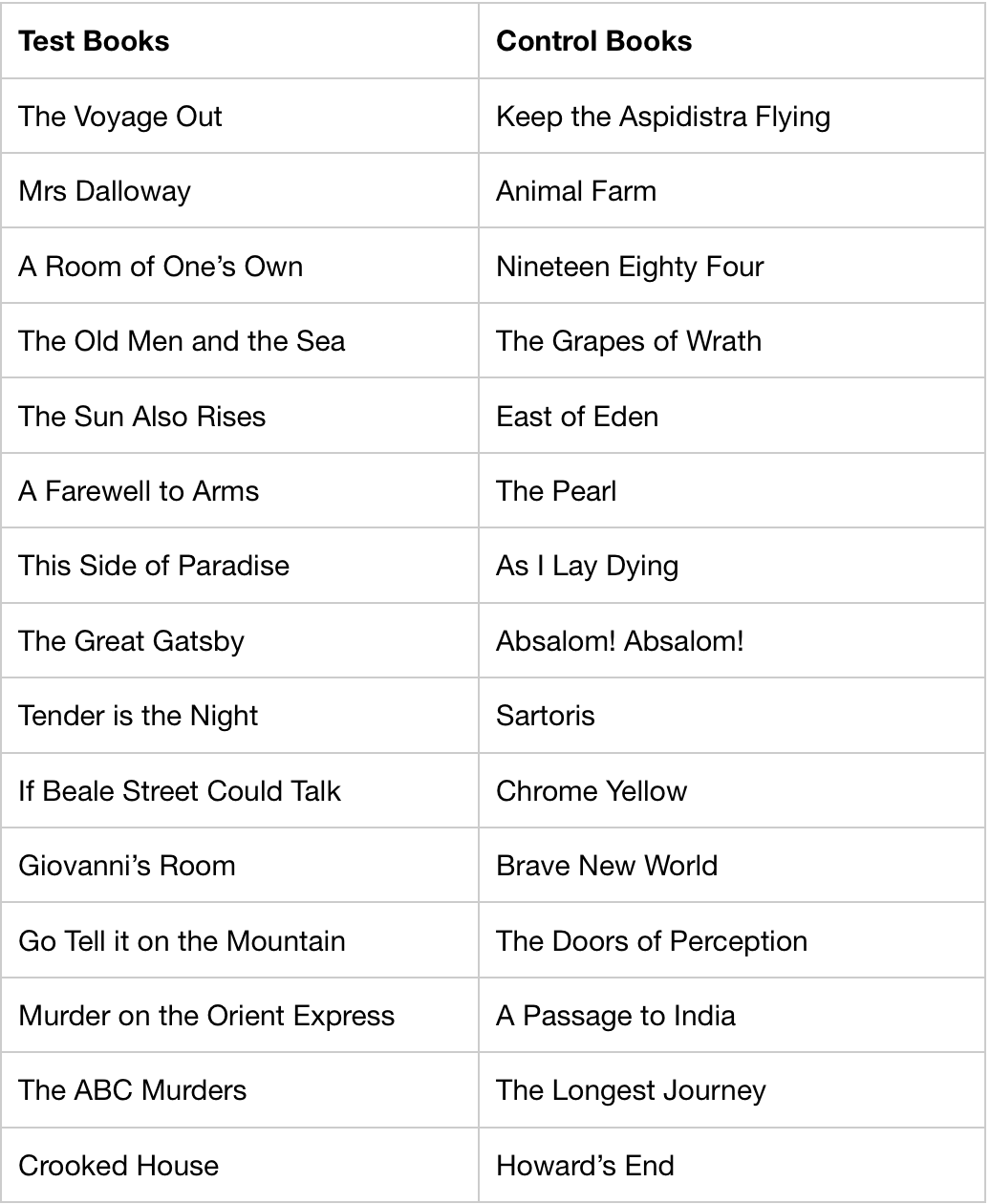
After a list of authors was compiled for both the test and control group (Table 1), three novels were chosen per author and exported as text files for processing. The date of novel publication and the birth year of the author were also tracked to determine the age of the author when the book was published.
Design and Computation
Several metrics were calculated per-book per-author to determine word frequency and pronoun use over time. All analytical code was written in Jupyter Notebooks with Python 3. Please refer to the python code here for detailed information on how certain values were calculated along with a spreadsheet of results and calculations.
First, all book text files were cleaned of punctuation and dropped down to lowercase to provide accurate results for the following steps. Dictionaries were then built for every text, with the words of every book and their respective frequencies. For example: ('the', 7367)
Then, in Step 1, This dictionary was sorted into an array ordered by how frequent a word was used (i.e. most frequent words came first, least frequent came last). In Step 2, matching arrays for each text were created to hold ordered rank info about each word. For example, if the word “the” was the most popular word in the book, it would receive a rank of “1”. Step 3 printed the top 20 used words each book and the number of times they were used.
Step 4 printed 3 scatter plots, one of each book, of the logarithm of the frequency of a given word against the logarithm of the word’s rank. These graphs give an illustration of a principle mentioned in Zipf’s Economy of Words, that word frequency follows a power law distribution based on the word’s frequency over its rank (Zipf, 1949). In Step 5, each plot’s slope was calculated by using a best-fit line.
Step 6 graphed the slope of the Zipf Coefficient against the age of the author at the time of writing the particular book, and the slope of the best-fit line for this plot was taken to see if there was any significant trend in this data.Step 7 calculated the number of times the word “I” (or rather ‘i’, since everything was done in lower case) was used in a text divided by the total words in the text and graphed this against the age of the author at the time of writing the given book. A slope of the outputted best-fit line for this graph was also recorded.
Results
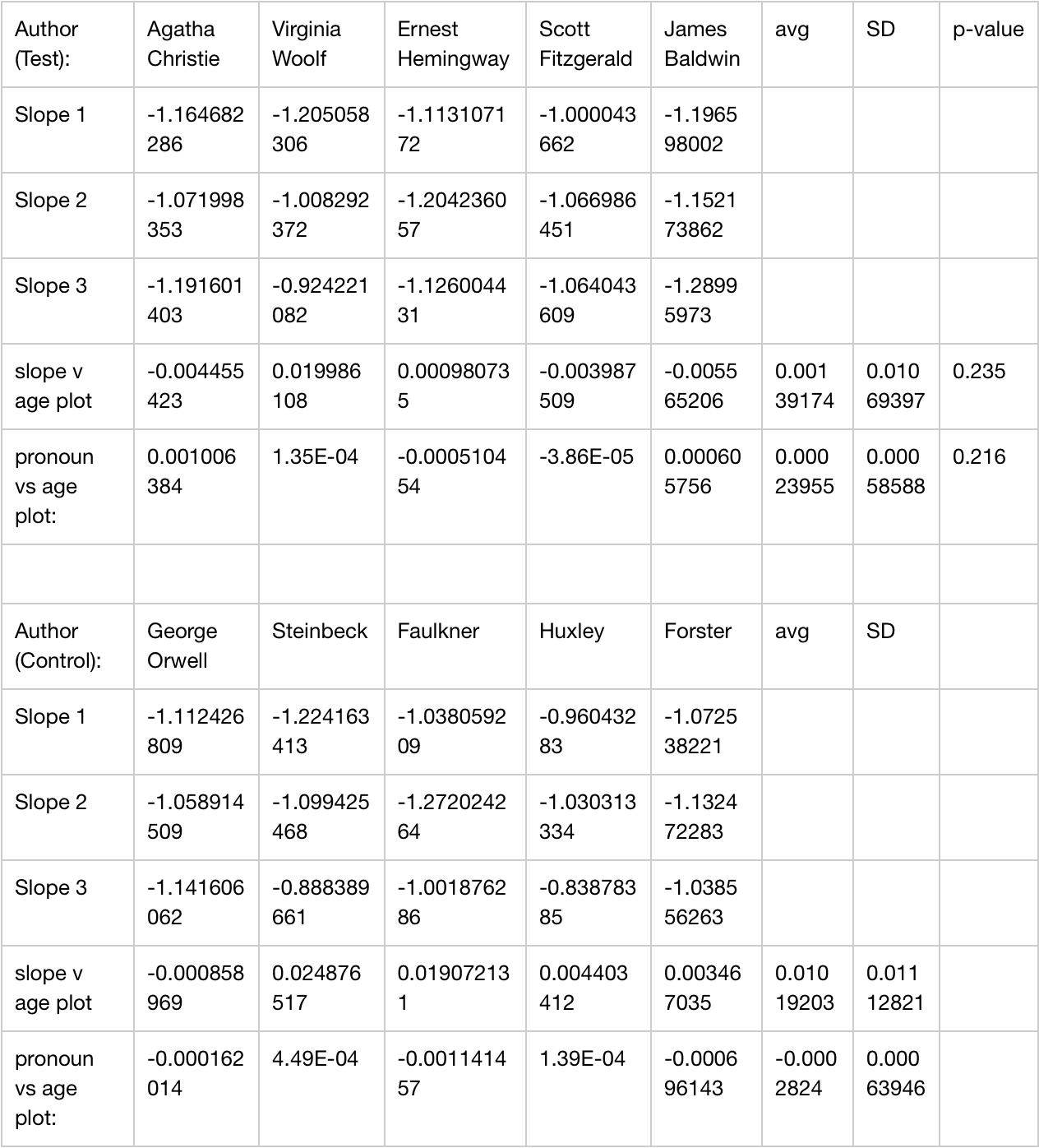
Detailed results based on the steps above for each book and each test can be seen in Table 3.
Of particular note is that the test group achieved a mean Zipf adherence over time of 0.00139 (SD = 0.01069) while the control group achieve a mean Zipf adherence of time of 0.01019 (SD = 0.01112). An independent samples t-test revealed a p-value of 0.235, indicating that the null primary hypothesis could not be rejected.
The test group achieved a mean change in first-person pronoun use over time of 0.00023 (SD = 0.00058) while the control group achieved a mean change in first-person pronoun use over time of -0.0002 (SD = 0.00063). An independent samples t-test revealed a p-value of 0.216 and, though statistically more significant than the Zipf adherence test above, the null secondary hypothesis could not be rejected.
Discussion
Based on the findings of this study detailed above, no concrete conclusion can be made about whether or not MDD causes shifts in word frequency over time in prose writing. Furthermore, the results proposed by several studies such as Edwards and Holtzman, 2017, Striman and Pennebaker, 2001, and Rude et al, 2004, among others, that individuals with depression use significantly more first person pronouns than those without, could not be validated. It is highly unlikely that this study overturns this previous research, rather the issues lie in the limitations of this experiment.
The single largest limitation of this study is the issue of data scarcity surrounding this topic. Data collection under so many necessary constraints was a challenge, though there is more data out there that would lend itself to collection and use in an expanded version of this study. Though there was enough data for each book to build strong word frequency distributions, as shown in a chart pulled from an author with a known history of depression (chart 1), there were not enough books surveyed per author to yield useful trends (chart 2).


Another limitation was that due to the lack of a formal diagnosis of MDD in individuals in the 19th and early 20th century, accompanied by a lack of medical records to corroborate with anecdotal evidence of depression, there is a distinct amount of uncertainty around whether or not the authors selected for the test group truly had MDD. The same goes for the test group. Depression can be hidden, and authors with no anecdotal evidence of MDD may not necessarily have been depression-free.
Conclusion and Future Direction
Future research would benefit from identifying a larger and more diverse population of authors, for both the control and the test group, to run this study on. Furthermore, attaining work from modern authors with confirmed cases of MDD and other modern authors with no history of mental health issues would allow for a significant reduction in uncertainty in the data set.
Another possible rewarding extension of this study would be to build a classifier, such a simple linear SVM based on the data-points collected from authors and books to accept an input of a few books from a given author and classify with a degree of certainty that the given author did or did not have MDD. Linear SVM (or a similar simple model) would be used due to the nature of the small data set and five-fold cross-validation would be used to ensure that the model is robust and to avoid overfitting. This extension would only be useful if a high enough degree of certainty across training and novel data is achieved with the model.
In conclusion, despite the current experiment contradicting previous studies about first-person pronoun use in depressed individuals, this is likely due to the weakness of the data set and not a result that invalidates previous findings.
Author’s note: This research was conducted for a cognitive science class during my undergrad at the University of Toronto. There are no conflicts of interest and this work has not been formally published - it’s just something that I found interesting and thought others might appreciate looking at as well. I hope to expand on this research in the future as at the completion of this research project it has become clear to me that a disease with a more formal diagnosis and a disease with a more well-understood neurodegenerative trajectory through time, might lend itself better to this kind of study. Depression is a very vast field of illness and categorizing past authors about whom biographers and contemporaries referred to as ‘depressed’ in a single box, is not representative of the population or of the authors themselves. I hope you enjoyed the work, if you have any questions about anything you read or feel that something needs clarification, please feel free to reach me at alex@alexgordienko.com or at @alexgordienko_.
References
Bernard, J. D., Baddeley, J. L., Rodriguez, B. F., & Burke, P. A. (2016). Depression, Language, and Affect: An Examination of the Influence of Baseline Depression and Affect Induction on Language. Journal of Language and Social Psychology, 35(3), 317–326. https://doi.org/10.1177/0261927X15589186
Edwards, T., & Holtzman, N. S. (2017). A meta-analysis of correlations between depression and first person singular pronoun use. Journal of Research in Personality, 68, 63–68. https://doi.org/https://doi.org/10.1016/j.jrp.2017.02.005
James, S. L., Abate, D., Abate, K. H., Abay, S. M., Abbafati, C., Abbasi, N., … Murray, C. J. L. (2018). Global, regional, and national incidence, prevalence, and years lived with disability for 354 Diseases and Injuries for 195 countries and territories, 1990-2017: A systematic analysis for the Global Burden of Disease Study 2017. The Lancet, 392(10159), 1789–1858. https://doi.org/10.1016/S0140-6736(18)32279-7
Philipp, M., Maier, W., & Delmo, C. D. (1991). The concept of major depression. European Archives of Psychiatry and Clinical Neuroscience, 240(4), 258–265. https://doi.org/10.1007/BF02189537
Rude, S., Gortner, E.-M., & Pennebaker, J. (2004). Language use of depressed and depression-vulnerable college students. Cognition and Emotion, 18(8), 1121–1133. https://doi.org/10.1080/02699930441000030
Szatloczki, G., Hoffmann, I., Vincze, V., Kalman, J., & Pakaski, M. (2015). Speaking in Alzheimer’s Disease, is That an Early Sign? Importance of Changes in Language Abilities in Alzheimer’s Disease. Frontiers in Aging Neuroscience, 7, 195. https://doi.org/10.3389/fnagi.2015.00195
Wiltsey Stirman, S., & Pennebaker, J. W. (2001). Word Use in the Poetry of Suicidal and Nonsuicidal Poets. Psychosomatic Medicine, 63(4).
Zipf, G. K. (1949). Human behavior and the principle of least effort: an introduction to human ecology. Addison-Wesley Press. Retrieved from https://books.google.ca/books?id=1tx9AAAAIAAJ
Appendix
Code
Once again, all of the code used in this research project can be found here: https://github.com/AlexGordienko/The-Effect-of-Neurodegenerative-Disease-on-the-Economy-of-Words